


¿Te acordás del misterioso modelo de edición de imágenes con IA “nano-banana” que fue tema de debate hace un tiempo? En ese momento, en la LMArena, el campo de batalla de los grandes modelos de lenguaje, se discutió mucho gracias a su destacada performance. Los expertos técnicos de Google Gemini también se turnaron para mostrarlo en redes sociales, generando mucha expectativa, e incluso llegó a rumorearse que era el supuesto Gemini 3.0 Pro.
Ahora, Google finalmente ha revelado su misterio.
En la madrugada del 27 de agosto (UTC+8), Google AI Studio lanzó oficialmente Gemini 2.5 Flash Image (nombre en clave nano banana) 🍌.
Gemini 2.5 Flash Image, que estuvo en pre-lanzamiento durante mucho tiempo, finalmente hace su aparición | Fuente de la imagen: GeekPark
Hasta ahora, este es el modelo de generación y edición de imágenes más avanzado de Google. No solo es increíblemente rápido, brindando una experiencia casi “relámpago”, sino que también ha alcanzado resultados SOTA en múltiples rankings, y en LMArena va muy por delante de la competencia.
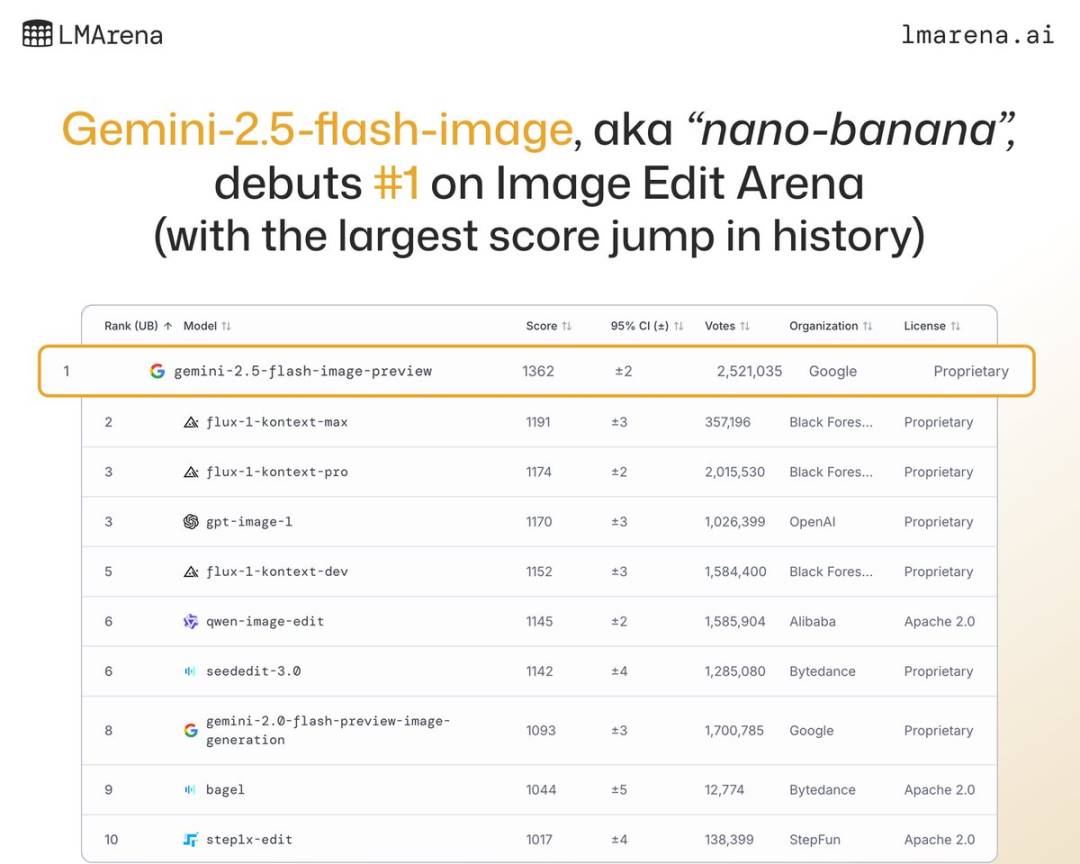
Gemini 2.5 Flash Image alcanza capacidades SOTA desde su lanzamiento | Fuente de la imagen: LMarena.ai
En su blog técnico, Google menciona que Gemini 2.0 Flash ya se había ganado el favor de los desarrolladores gracias a su baja latencia y alta relación costo-beneficio, pero los usuarios siempre esperaron imágenes de mayor calidad y un control creativo más potente. Gemini 2.5 Flash Image llega con estas mejoras clave: la coherencia de roles finalmente se mantiene plenamente, la edición de imágenes basada en prompts es más precisa, la fusión de múltiples imágenes es natural y fluida, y su comprensión del conocimiento del mundo real lo convierte no solo en un modelo, sino en el “punto de partida” para la próxima generación de aplicaciones exitosas.
En GeekPark también lo probamos de inmediato. Para sorpresa nuestra, esto no es solo una actualización de modelo: por primera vez, se siente que el futuro de la edición de imágenes con IA está a la vuelta de la esquina.
Actualmente ya está disponible para probar en Google AI Studio | Fuente de la imagen: GeekPark
Al principio, solo tenía la intención de hacer una prueba convencional, “ver qué tan rápido es el nuevo modelo”. Pero no esperaba que, en solo unas horas de uso, pudiera vislumbrar cómo serán las aplicaciones exitosas de la próxima generación.
Antes, estábamos acostumbrados a herramientas como Meitu XiuXiu: tocás un botón, aplicás un filtro y la foto mejora al instante. Pero la sensación que da Gemini 2.5 Flash Image es completamente diferente. Es increíblemente rápido, inteligente como un diseñador que entiende lo que querés, y solo necesitás decirle el efecto que buscás para que, en segundos, te lo muestre en pantalla.

Además del resultado, la velocidad es otra diferencia notable de Gemini 2.5 Flash Image respecto a modelos anteriores | Fuente de la imagen: GeekPark
01 Generación ultra rápida, resultados en segundos
Lo más directo de la experiencia nano banana es la velocidad. Antes, usando algunos modelos open source, aunque tuvieras una buena computadora, desde que ingresabas el prompt hasta que obtenías una imagen decente, podías esperar decenas de segundos o más. Para usuarios de móvil, la espera era aún más tediosa.
Pero Gemini 2.5 Flash Image baja esa barrera a solo unos segundos. Es el modelo multimodal nativo “más nuevo, rápido y eficiente” según Google, y se nota que han optimizado mucho. En mis pruebas, con solo ingresar un prompt, en tres o cuatro segundos ya tenía el resultado (UTC+8), con una resolución y detalles muy nítidos.
La experiencia se parece a usar Meitu XiuXiu: tocás el botón de “embellecer” y el efecto es casi instantáneo. La diferencia es que Meitu XiuXiu aplica un filtro con un algoritmo, mientras que Gemini 2.5 Flash Image construye una imagen desde cero o transforma una foto según tus necesidades. Esa sensación de “apuntar y disparar” es algo que los procesos tradicionales de edición nunca pudieron ofrecer.

Para necesidades como “eliminar personas del fondo”, solo necesitás un prompt | Fuente de la imagen: GeekPark
Si la velocidad resuelve la experiencia del usuario tradicional de edición, la “multimodalidad nativa” amplía los límites de la capacidad de imágenes de la IA.
Gemini 2.5 Flash Image no solo genera imágenes, también entiende entradas de texto e imagen al mismo tiempo. Esto significa que podés darle una foto y un prompt, y combinará ambas informaciones para entender exactamente lo que querés.
Por ejemplo, subí una foto tomada en la calle y le pedí “cambiá el fondo por una vista nocturna de Shinjuku, Tokio” (UTC+8). No solo reconoció el sujeto principal de la foto, sino que lo recortó perfectamente y reemplazó el fondo por las luces de neón de Shinjuku. Lo más destacable es que mantuvo la coherencia de luces y sombras en la persona, sin el típico efecto artificial de recorte manual.
Esta capacidad me recuerda a la función de “cambiar fondo con un clic” que los fabricantes de móviles han promocionado en sus galerías en los últimos años. Pero antes, el cambio de fondo solía dejar bordes borrosos y luces poco realistas. Ahora, Gemini 2.5 Flash Image usa conocimiento del mundo y comprensión visual para mejorar esos detalles, logrando resultados mucho más naturales y conservando detalles que los modelos tradicionales de texto-a-imagen o imagen-a-imagen no podían.

Imagen original & resultado generado por Gemini 2.5 Flash Image | Fuente de la imagen: GeekPark
Por eso creo que redefine la experiencia de edición: ya no dependés de muchos ajustes manuales, sino que el modelo entiende el significado natural y realiza la tarea de manera “potente”, por ejemplo, en retratos donde los detalles son clave.

Para este tipo de retoque de retratos, la coherencia de roles de Gemini 2.5 Flash Image realmente ofrece una experiencia de “Vibe Photoshoping” nunca antes vista.

En un segundo ayuda a los programadores a “salvar la dignidad” | Fuente de la imagen: GeekPark
Esta experiencia rompe con la vieja impresión de la generación de imágenes con IA: “esotérica”; si el prompt es bueno, el resultado es sorprendente; si es regular, el resultado puede ser cualquier cosa.
Pero en Gemini 2.5 Flash Image, noté que esa “sensación esotérica” se redujo mucho. Entiende los prompts con más precisión y se acerca más a la intuición del usuario, por eso muchos sienten que es mucho más útil.
Por ejemplo, le pedí “desenfocá el fondo y destacá la persona en primer plano” (UTC+8), y en segundos generó justo lo que quería; le pedí “cambiá la expresión de la persona en la foto por una sonrisa”, y no solo levantó la comisura de los labios, sino que también ajustó la mirada, con mucho detalle; incluso probé “coloreá una foto en blanco y negro”, y el resultado no fue un manchón de colores, sino que intentó acercarse a la atmósfera cromática de las fotos históricas.
Esta capacidad de “decir y hacer” me recuerda cuando usaba Meitu XiuXiu: solo quería suavizar la piel y terminaba con una cara falsa de “belleza nivel 10”. Ahora, las operaciones de Gemini 2.5 Flash Image son precisas y moderadas: realmente entiende lo que querés y lo reproduce lo mejor posible.
02 Capacidades mejoradas, después de usarlo no hay vuelta atrás
Para ser más claro, lo comparé con mis herramientas móviles de edición habituales.
En Snapseed, si quiero desenfocar el fondo, tengo que seleccionar manualmente el área del primer plano y ajustar el desenfoque, lo que lleva uno o dos minutos y varias correcciones.
En Meitu XiuXiu, aunque hay una función de desenfoque de fondo con un clic, a menudo desenfoca también los bordes de la persona y el resultado no es natural.
En Gemini 2.5 Flash Image, solo necesito decirlo y reconoce automáticamente los límites entre persona y fondo, el desenfoque es natural y no requiere retoques adicionales.

Al cambiar detalles de la imagen, evita el “manoseo” que solía ocurrir con otras herramientas de IA | Fuente de la imagen: Twitter
Esta comparación demuestra algo: Gemini 2.5 Flash Image libera al usuario de operaciones complejas y delega más trabajo al modelo. Para la gente común, baja la barrera de entrada; para los profesionales, ahorra mucho tiempo.
Después de probarlo, mi mayor impresión es que Gemini 2.5 Flash Image ya no es solo una herramienta de edición, sino más bien un “asistente inteligente”.
Antes, usábamos Meitu XiuXiu como un conjunto de funciones preestablecidas: filtros, embellecimiento, mosaico, cada botón tenía una función. Solo había que elegir y ajustar hasta estar conforme.
Ahora, la lógica de Gemini 2.5 Flash Image es completamente diferente. Ya no tenés que aprender cómo funciona la herramienta, sino que entiende directamente lo que necesitás. Solo tenés que decirlo y lo hace por vos.
Este cambio parece sutil, pero en realidad transforma por completo la relación en el proceso de edición. Antes nos adaptábamos a la herramienta, ahora la herramienta se adapta a nosotros. Esta forma de interactuar es el prototipo de la próxima generación de aplicaciones.
Hoy por hoy, Gemini 2.5 Flash Image todavía está en una etapa temprana y puede tener limitaciones funcionales. Pero la velocidad, comprensión y fidelidad que muestra ya son suficientes para imaginar el futuro.
¿Qué pasaría si se combinara con Meitu XiuXiu? Tal vez abras la app, le digas al móvil “mejorá esta foto, hacé que la piel se vea natural”, y en segundos tenés el resultado (UTC+8); o cuando sacás fotos de viaje, le decís “cambiá el clima a soleado” (UTC+8) y la foto se vuelve luminosa; incluso en edición de video, podrías cambiar el ambiente de un clip con una sola frase.

Este método podría convertirse rápidamente en la función principal de edición de imágenes en los sistemas operativos móviles | Fuente de la imagen: Twitter
Por eso creo que revolucionará rápidamente los flujos de trabajo de las herramientas de edición, definiendo la próxima generación de “Meitu XiuXiu”: no solo edición, sino una nueva forma de interactuar con la imagen, haciendo que la IA sea tu compañera en la postproducción fotográfica.
Pero por ahora, Gemini 2.5 Flash Image aún no puede ser una app de edición masiva lista para usar: no solo porque su objetivo principal sigue siendo la generación de imágenes y no el retoque sobre una base existente, sino porque todas las imágenes creadas o editadas con Gemini 2.5 Flash Image incluyen una marca de agua digital SynthID, para que las plataformas sociales puedan identificar contenido generado por IA.
03 El punto de explosión de un éxito viral
Si lo pensamos, Meitu XiuXiu se convirtió en una app masiva porque resolvió de la manera más simple el problema que todos querían solucionar: hacer que las fotos se vean mejor.
Gemini 2.5 Flash Image va un paso más allá, puliendo la compleja capacidad de IA para que cualquiera pueda tener una experiencia de “imagen en segundos”.
La primera vez que le dije “ayudame a desenfocar el fondo” (UTC+8) y en segundos la imagen quedó perfecta, supe que ese era el punto de partida de una app viral. No es solo un modelo, sino la base de innumerables productos futuros.
La función de cambiar el cielo con IA, que fue furor entre usuarios de móviles hace unos años | Fuente de la imagen: comunidad vivo
Quizás en unos años olvidemos el nombre Banana, pero veremos cada vez más herramientas de edición de imágenes que te permiten “decir lo que querés y lograrlo al instante”, y tal vez, como Meitu XiuXiu en su momento, se conviertan en el recuerdo compartido de toda una generación de usuarios.
Solo que esta vez, la IA llevará la imaginación mucho más lejos.