
From Clearing Storm to Cloud Outage: The Crisis Moment of Crypto Infrastructure

On the 20th, an AWS issue at Amazon caused Coinbase and dozens of other major crypto platforms including Robinhood, Infura, Base, and Solana to experience downtime.
Original Title: Crypto Infrastructure is Far From Perfect
Original Author: YQ, Crypto KOL
Original Translation: AididiaoJP, Foresight News
Amazon Web Services has once again experienced a significant outage, severely affecting the crypto infrastructure. The AWS issue in the US East Region (Northern Virginia data center) caused major crypto platforms including Coinbase, as well as Robinhood, Infura, Base, and Solana, to be paralyzed.
AWS has acknowledged the impact on Amazon DynamoDB and EC2 with an "increase in error rates," which are core databases and computing services relied upon by thousands of companies. This outage provides immediate and stark validation of the central thesis of this article: the crypto infrastructure's reliance on centralized cloud service providers has created systemic vulnerabilities that are repeatedly exposed under stress.
The timing of this event is sobering. Just ten days after a $193 billion liquidation cascade exposed infrastructure failures at the exchange level, today's AWS outage demonstrates that the issue has expanded beyond individual platforms to the foundational layer of cloud infrastructure. When AWS faces disruptions, the cascading impact simultaneously affects centralized exchanges, "decentralized" platforms with centralized dependencies, and countless other services.
This is not an isolated incident but a pattern. The following analysis documents similar AWS outage events in April 2025, December 2021, and March 2017, each resulting in a major crypto service outage. The concern is not whether the next infrastructure failure will occur but when and what the triggering factors will be.
October 10-11, 2025 Liquidation Cascade Event: A Case Study
The October 10-11, 2025, liquidation cascade event provides an enlightening case study of the infrastructure failure pattern. At UTC 20:00, a significant geopolitical announcement triggered a market-wide sell-off. Within one hour, a $60 billion liquidation occurred. By the opening of the Asian markets, $193 billion in leveraged positions had been liquidated from 1.6 million trader accounts.
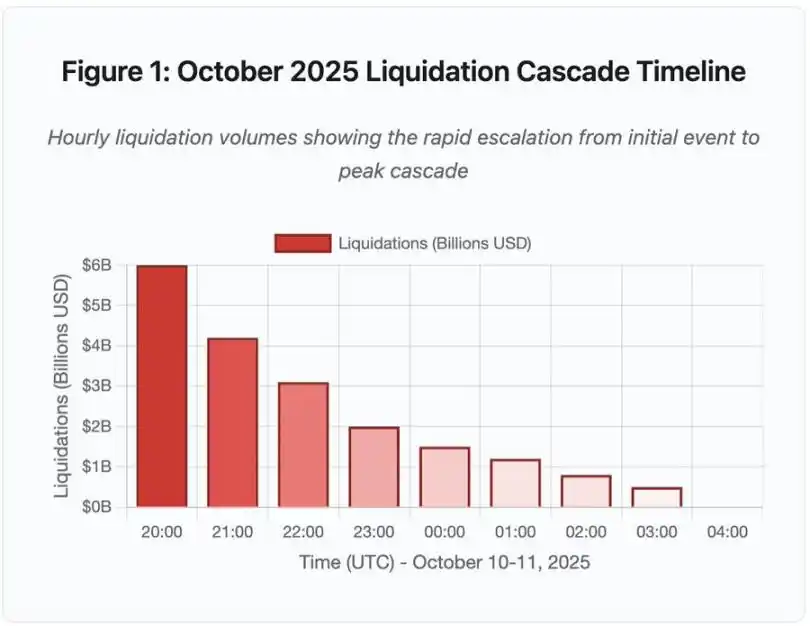
Figure 1: October 2025 Clearing Cascade Event Timeline
This interactive timeline chart illustrates the dramatic progression of settlement amounts per hour. A staggering $60 billion evaporated in just the first hour, followed by even more intense cascading in the second hour. The visualization shows:
· 20:00-21:00: Initial Impact - $60 billion settled (red zone)
· 21:00-22:00: Cascade Peak - $42 billion, with API rate limiting beginning at this point
· 22:00-04:00: Ongoing Deterioration - $91 billion settled in a liquidity-starved market
· Key Turning Points: API Rate Limits, Market Maker Withdrawals, Order Book Thinning
Its scale is at least an order of magnitude larger than any previous crypto market event, and historical comparisons showcase the step-function nature of this event:
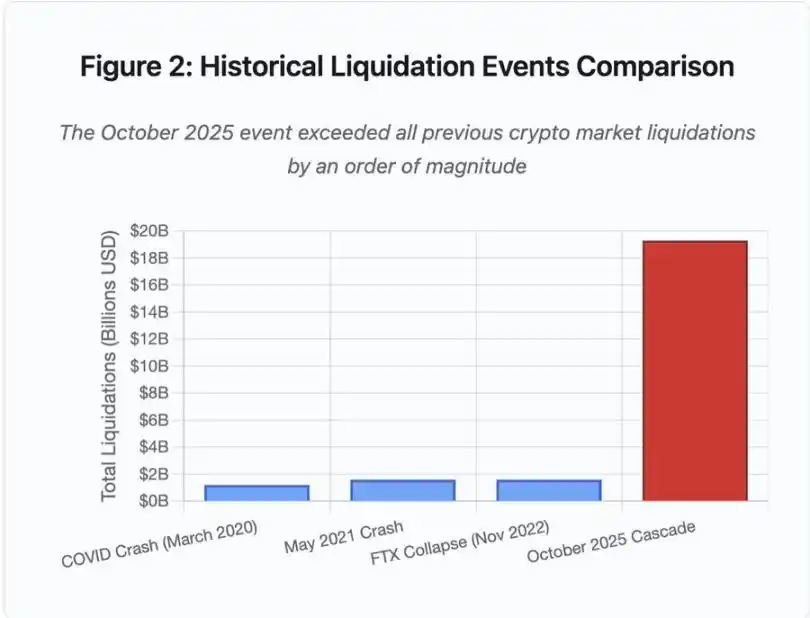
Figure 2: Historical Clearing Event Comparison
A bar chart dramatically illustrates the prominence of the October 2025 event:
· March 2020 (COVID): $12 billion
· May 2021 (Flash Crash): $16 billion
· November 2022 (FTX): $16 billion
· October 2025: $193 billion, a staggering 16x increase over the previous record
However, the settlement figures only tell part of the story. The more intriguing questions revolve around the mechanism: how did external market events trigger this specific failure mode? The answer reveals systemic weaknesses in both centralized exchange platform infrastructure and blockchain protocol design.
Off-Chain Failure: Centralized Exchange Platform Architecture
Infrastructure Overload and Rate Limiting
Exchange platform APIs enforce rate limits to prevent abuse and manage server loads. During normal operations, these limits allow legitimate transactions while thwarting potential attacks. In periods of extreme volatility, when thousands of traders are simultaneously trying to adjust positions, these same rate limits become bottlenecks.
CEX limited its settlement notifications to one per second, even when processing thousands of orders per second. During the October chain event, this led to opaqueness. Users were unable to gauge the real-time severity of the chain congestion. Third-party monitoring tools indicated hundreds of settlements per minute, while official data sources showed a much lower number.
API rate limits prevented traders from adjusting positions within the critical first hour, leading to connection request timeouts and failed order submissions. Stop-loss orders failed to execute, position inquiries returned outdated data, and this infrastructure bottleneck turned a market event into an operational crisis.
Traditional trading platforms provision infrastructure with normal load plus security margin. However, normal load is vastly different from stress load, and daily trading volume cannot predict peak stress demand well. During the chain event, trading volume increased by 100 times or more, queries for position data surged by 1000 times, as each user simultaneously checked their account.
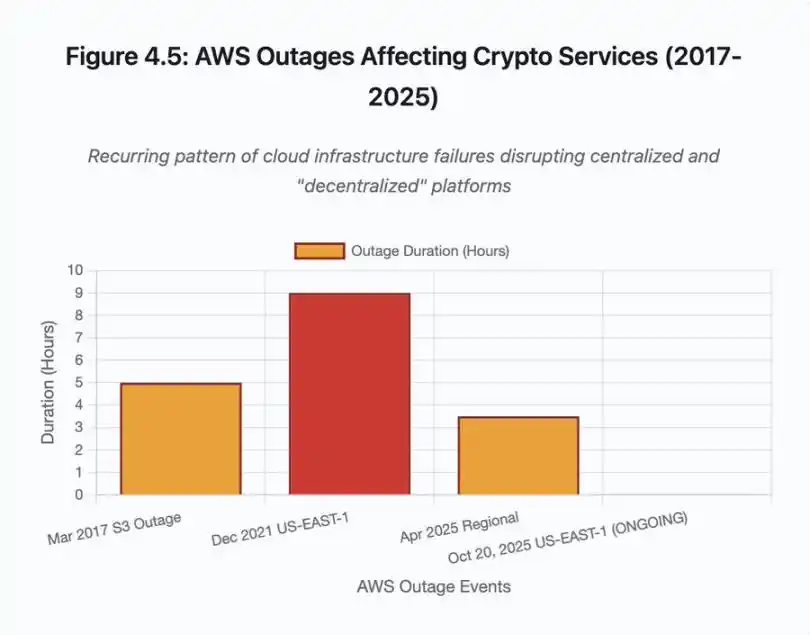
Figure 4.5: AWS Outage Impacting Crypto Services
Auto-scaling cloud infrastructure helped to some extent but could not respond instantaneously. It took minutes to spin up additional database read replicas. Creating new API gateway instances took minutes. During those minutes, the margin system continued marking positions based on corrupt price data from the overloaded order book.
Oracle Manipulation and Pricing Vulnerability
During the chain event in October, a key design choice in the margin system became evident: some exchanges based collateral valuations on internal spot market prices rather than external oracle data feeds. Under normal market conditions, arbitrageurs maintain price consistency across venues. However, when the infrastructure is under stress, this coupling breaks down.

Figure 3: Oracle Manipulation Process Diagram
This interactive process diagram visualizes the attack vector in five stages:
· Initial Dump: Exerting $60 million selling pressure on USDe
· Price Manipulation: USDe plunging from $1.00 to $0.65 on a single exchange
· Oracle Failure: Margin system using a corrupted internal price feed
· Cascading Liquidation: Collateral marked down triggers forced liquidations
· Amplification: $19.3 billion total liquidation (amplified 322x)
The attack exploited Binance's use of spot market pricing for wrapped synthetic collateral. When the attacker dumped $60 million of USDe into a relatively illiquid order book, the spot price plummeted from $1.00 to $0.65. The margin system, configured to mark collateral by spot price, devalued all USDe-collateralized positions by 35%. This triggered margin calls and forced liquidations for thousands of accounts.
These liquidations forced more sell orders into the same illiquid market, further driving down the price. The margin system observed these lower prices and marked down more positions, creating a feedback loop that amplified $60 million in selling pressure into $19.3 billion in forced liquidations.

Figure 4: Liquidation Cascade Feedback Loop
This feedback loop diagram illustrates the self-reinforcing nature of the cascade:
Price drop → Trigger liquidation → Forced selling → Further price drop → [Repeat]
If a well-designed oracle system were in place, this mechanism would not function. If Binance had used a time-weighted average price (TWAP) across multiple exchanges, the instantaneous price manipulation would not impact collateral valuations. If they had utilized an aggregated price feed from Chainlink or other multi-source oracles, the attack would have failed.
A similar vulnerability was showcased in the wBETH event four days prior. wBETH was supposed to maintain a 1:1 peg to ETH. During the cascading event, liquidity dried up, leading to a 20% discount in the wBETH/ETH spot market. The margin system accordingly marked down wBETH collateral valuations, triggering liquidations of positions effectively fully collateralized by underlying ETH.
Automatic Deleveraging (ADL) Mechanism
When liquidation cannot be executed at the current market price, exchanges implement Automatic Deleveraging (ADL) to socialize losses among profitable traders. ADL forcefully closes out profitable positions at the current price to offset the shortfall from liquidated positions.
During the October Flash Crash event, Binance conducted Auto-Deleveraging (ADL) on multiple trading pairs. Traders holding profitable long positions found their trades being liquidated not due to their own risk management failures, but because other traders' positions became undercollateralized.
ADL reflects a fundamental architectural choice in centralized derivative exchanges. The trading platform ensures it does not lose money. This means losses must be absorbed by one or more of the following:
· Insurance Fund (funds reserved by the trading platform to cover liquidation shortfalls)
· ADL (auto-deleverage of profitable traders)
· Socialized Loss (spreading the loss across all users)
The size of the Insurance Fund relative to the open interest determines the frequency of ADL. Binance's Insurance Fund totaled around $2 billion in October 2025. This provided a 50% coverage relative to the $4 billion open interest in BTC, ETH, and BNB perpetual contracts. However, during the October Flash Crash event, the total open interest across all trading pairs exceeded $20 billion. The Insurance Fund couldn't cover the shortfall.
Following the October Flash Crash event, Binance announced that they guarantee no ADL would occur on BTC, ETH, and BNB USDⓈ-M contracts as long as the total open interest remains below $4 billion. This created an incentive structure: the trading platform can maintain a larger Insurance Fund to avoid ADL, but this would tie up funds that could have been deployed for profit.
On-Chain Failure: Limitations of Blockchain Protocols
The bar graph compares downtime in different events:
· Solana (February 2024): 5 hours - Vote Throughput Bottleneck
· Polygon (March 2024): 11 hours - Validator Version Mismatch
· Optimism (June 2024): 2.5 hours - Sequencer Overload (Airdrop)
· Solana (September 2024): 4.5 hours - Transaction Spam Attack
· Arbitrum (December 2024): 1.5 hours - RPC Provider Outage
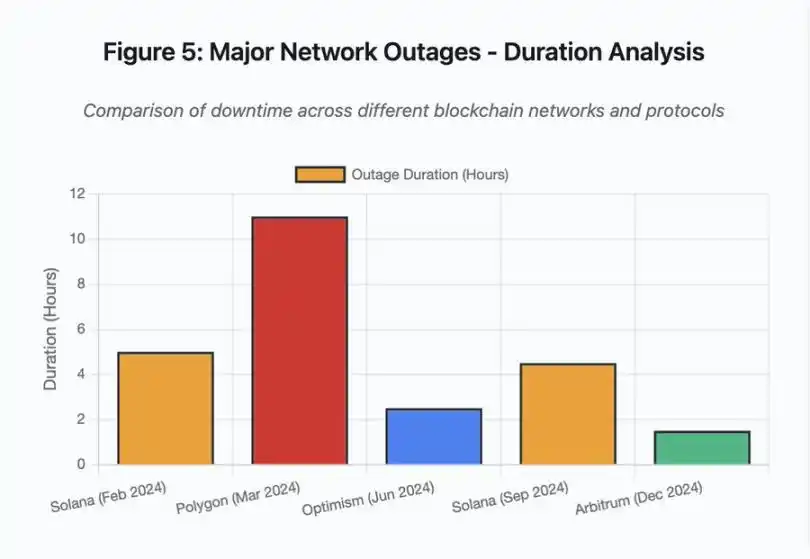
Figure 5: Major Network Outage - Duration Analysis
Solana: Consensus Bottleneck
Solana experienced multiple outages during the 2024-2025 period. The outage in February 2024 lasted approximately 5 hours, while the outage in September 2024 lasted 4-5 hours. These outages stemmed from similar root causes: the network couldn't handle the transaction volume during a spam attack or extreme activity.
Figure 5 Details: Solana's outages (5 hours in February, 4.5 hours in September) highlighted the recurring issue of network resilience under pressure.
Solana's architecture is optimized for throughput. Under ideal conditions, the network processes 3,000-5,000 transactions per second and achieves sub-second finality. This performance is orders of magnitude higher than Ethereum. However, during stress events, this optimization created vulnerabilities.
The September 2024 outage was triggered by a wave of spam transactions that overwhelmed the validators' voting mechanism. Solana validators must vote on blocks to achieve consensus. During normal operation, validators prioritize processing vote transactions to ensure consensus progression. However, the protocol had previously treated vote transactions as regular transactions in the fee market.
When the transaction mempool was filled with millions of spam transactions, validators struggled to propagate vote transactions. Without enough votes, blocks couldn't finalize. Without finalized blocks, the chain halted. Users with transactions pending saw them stuck in the mempool. New transactions couldn't be submitted.
StatusGator documented multiple Solana service outages in 2024-2025, which Solana never officially acknowledged. This created information asymmetry. Users couldn't distinguish between local connectivity issues and network-wide problems. Third-party monitoring services offered accountability, but the platform should maintain a comprehensive status page.
Ethereum: Gas Fee Explosion
Ethereum experienced an extreme Gas fee surge during the 2021 DeFi boom, with transaction fees for simple transfers exceeding $100. Complex smart contract interactions cost between $500-$1,000. These fees made the network unusable for smaller transactions and also enabled a different attack vector: MEV extraction.
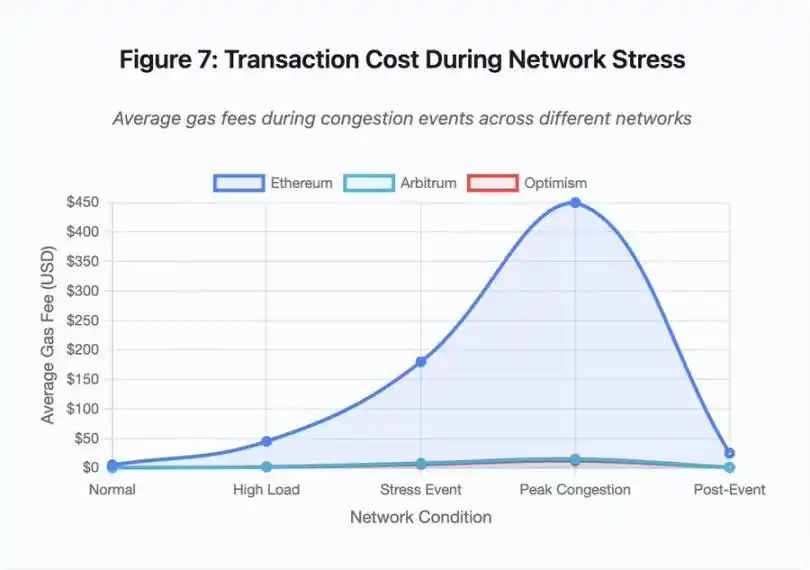
Figure 7: Transaction Costs During Network Stress
This line chart dramatically illustrates the Gas fee increases across various networks during stress events:
· Ethereum: $5 (normal) → $450 (peak congestion) - 90x increase
· Arbitrum: $0.50 → $15 - 30x increase
· Optimism: $0.30 → $12 - 40x increase
The visualization shows that even Layer 2 solutions experienced significant Gas fee spikes, albeit starting from a much lower base.
Maximum Extractable Value (MEV) describes the profit validators can extract by reordering, including, or excluding transactions. In a high Gas fee environment, MEV becomes particularly lucrative. Arbitrageurs race to front-run large DEX trades, liquidation bots race to liquidate undercollateralized positions first. This competition manifests as a Gas fee auction.
Users looking to ensure their transactions are included during congestion must bid higher than MEV bots. This has led to scenarios where transaction fees exceed the transaction value. Want to claim your $100 airdrop during peak traffic? Pay a $150 Gas fee. Need to add collateral to avoid liquidation? Compete with a bot paying a $500 priority fee.
Ethereum's Gas limit constrains the total computational load per block. During congestion, users bid for scarce block space. The fee market works as designed: the highest bidder wins. However, this design has made the network increasingly expensive during periods of high usage, precisely when users need access the most.
Layer 2 solutions aim to address this issue by moving computation off-chain while inheriting Ethereum's security through periodic settlements. Optimism, Arbitrum, and other Rollups process thousands of transactions off-chain and then submit compressed proofs to Ethereum. This architecture has successfully reduced transaction costs during normal operation.
Layer 2: Sequencer Bottleneck
However, Layer 2 solutions have introduced a new bottleneck. In June 2024, Optimism experienced an interruption when 250,000 addresses simultaneously claimed an airdrop. The sequencer, a component that sorts transactions before submitting them to Ethereum, buckled under the load, leaving users unable to submit transactions for several hours.
This outage demonstrates that moving computation off-chain does not eliminate infrastructure requirements. The sequencer must process incoming transactions, order them, execute them, and generate fraud proofs or ZK proofs for Ethereum settlement. Under extreme load, the sequencer faces the same scaling challenges as an independent blockchain.
It is crucial to maintain the availability of multiple RPC providers. If the primary provider fails, users should seamlessly failover to an alternative. During the Optimism outage, some RPC providers remained functional, while others failed. Users connected to a failed provider by default were unable to interact with the chain, even if the chain itself was still online.
AWS outages have repeatedly demonstrated the existence of centralized infrastructure risk in the crypto ecosystem:
· October 20, 2025 (today): The US East 1 region outage affected Coinbase, as well as Venmo, Robinhood, and Chime. AWS acknowledged increased error rates for DynamoDB and EC2 services.
· April 2025: A regional outage simultaneously impacted Binance, KuCoin, and MEXC. When its AWS-hosted components failed, multiple major exchanges became unavailable.
· December 2021: A US East 1 region outage resulted in an 8-9 hour outage for Coinbase, Binance.US, and the "decentralized" exchange dYdX, concurrently affecting Amazon's own warehouses and major streaming services.
· March 2017: An S3 outage prevented users from logging into Coinbase and GDAX for five hours, accompanied by widespread internet disruptions.
The pattern is clear: these exchanges host critical components on AWS infrastructure. When AWS experiences a regional outage, multiple major exchanges and services simultaneously become unavailable. Users are unable to access funds, execute trades, or adjust positions during the outage, precisely when market volatility may require immediate action.
Polygon: Consensus Version Mismatch
Polygon (formerly Matic) experienced an 11-hour outage in March 2024. The root cause involved a mismatch in validator versions, with some validators running old software versions and others running upgraded versions. These versions computed state transitions differently.
Figure 5 Detail: The Polygon outage (11 hours) was the longest in the analyzed major events, highlighting the severity of a consensus failure.
When validators reach different conclusions about the correct state, a consensus failure occurs, and the chain is unable to produce new blocks because validators cannot agree on block validity. This results in a deadlock: validators running old software refuse blocks produced by validators running new software, while validators running new software refuse blocks produced by validators running old software.
Resolving this requires coordinating validator upgrades, but coordinating validator upgrades during a disruption takes time. Each validator operator must be contacted, the correct software version must be deployed, and the validator must be restarted. In a decentralized network with hundreds of independent validators, this coordination can take hours or days.
Hard forks typically use a block height trigger. All validators upgrade before a specific block height to ensure simultaneous activation, but this requires coordination beforehand. Incremental upgrades, where validators gradually adopt the new version, pose a risk of exact version mismatch that could lead to a Polygon disruption.
Architectural Trade-offs
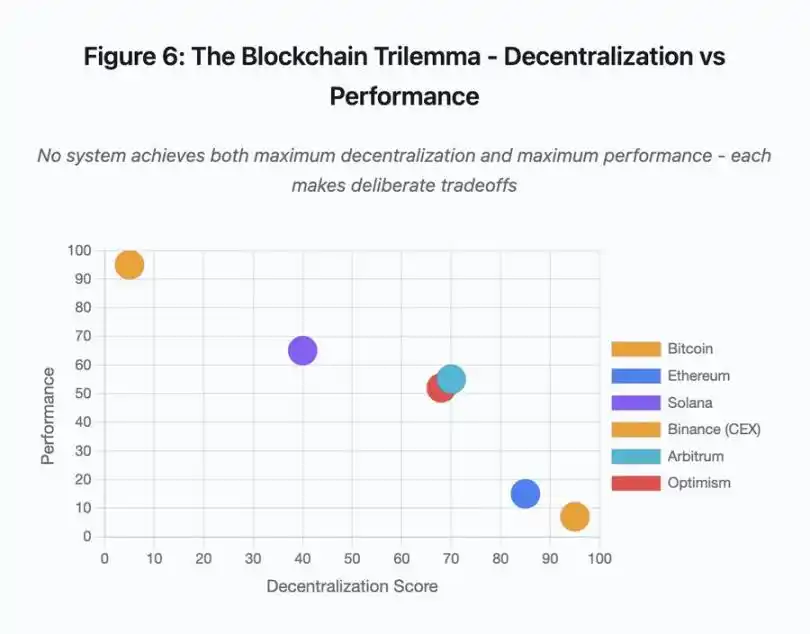
Figure 6: Blockchain Trilemma - Decentralization vs. Performance
This scatter plot visualizes different systems mapped along two key dimensions:
· Bitcoin: High decentralization, low performance
· Ethereum: High decentralization, moderate performance
· Solana: Moderate decentralization, high performance
· Binance (CEX): Minimal decentralization, maximal performance
· Arbitrum/Optimism: Medium-high decentralization, moderate performance
Key Insight: No system can achieve maximal decentralization and maximal performance simultaneously; each design has carefully considered trade-offs for different use cases.
Centralized exchanges achieve low latency through architectural simplicity, with order matching engines processing orders in microseconds, and state residing in a centralized database. No consensus protocol introduces overhead, but this simplicity creates single points of failure, and under stress, cascading failures propagate through tightly coupled systems.
Decentralized protocols distribute state among validators, eliminating single points of failure. High-throughput chains maintain this property during disruptions (funds remain secure, only liveness temporarily affected). However, reaching consensus among distributed validators introduces computational overhead, as validators must agree before state transitions are deemed final. When validators run incompatible versions or face overwhelming traffic, the consensus process may temporarily pause.
Adding replicas improves fault tolerance but increases coordination costs. In a Byzantine fault-tolerant system, each additional validator will increase communication overhead. High-throughput architectures minimize this overhead through optimized validator communication to achieve superior performance but are susceptible to certain attack patterns. Security-focused architectures prioritize validator diversity and consensus robustness, limiting base-layer throughput while maximizing resilience.
Layer 2 solutions seek to provide these two attributes through a layered design. They inherit Ethereum's security properties through L1 settlement while offering high throughput through off-chain computations. However, they introduce new bottlenecks at the sequencer and RPC layers, indicating that architectural complexity, while solving some problems, creates new failure modes.
Scaling Remains a Fundamental Issue
These events reveal a consistent pattern: systems are resource-configured for normal loads and catastrophically fail under stress. Solana effectively handled regular traffic but crashed when transaction volume surged by 10,000%. Ethereum gas fees remained reasonable until DeFi adoption triggered congestion. Optimism's infrastructure ran smoothly until 250,000 addresses simultaneously claimed an airdrop. Binance's API functioned well during normal trading but faced restrictions during liquidation cascades.
The events of October 2025 showcased this dynamic at the exchange level. During normal operations, Binance's API rate limits and database connections were sufficient, but during liquidation cascades, when every trader attempted to adjust positions simultaneously, these limits became bottlenecks. Intended to protect exchanges through forced liquidation of margin systems, creating forced sellers at the worst possible moment amplified the crisis.
Automated scaling provides inadequate protection against step-function increases in load. Spinning up additional servers takes minutes, during which the margin system marks position values based on corrupted price data from a thin order book; by the time new capacity comes online, the cascade reaction has already spread.
Overprovisioning resources for rare stress events incurs costs during normal operations. Exchange operators optimize for typical loads, accepting occasional failures as an economically rational choice. The cost of downtime is externalized to users, who experience liquidations, stuck trades, or fund inaccessibility during critical market movements.
Infrastructure Improvements
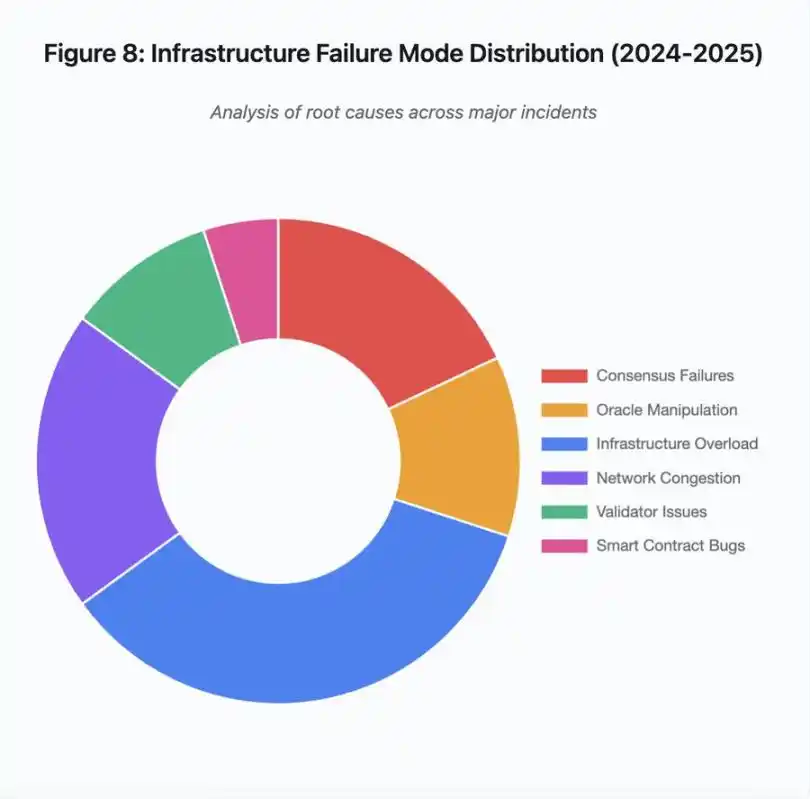
Figure 8: Infrastructure Failure Mode Distribution (2024-2025)
Root Cause Pie Chart Breakdown:
· Infrastructure Overload: 35% (Most Common)
· Network Congestion: 20%
· Consensus Failure: 18%
· Oracle Manipulation: 12%
· Validator Issues: 10%
· Smart Contract Vulnerabilities: 5%
Several architectural changes can reduce the frequency and severity of failures, although each involves trade-offs:
Separation of Pricing System and Settlement System
The October issue partly stemmed from coupling margin calculations to spot market prices. Using exchange rates for wrapped assets instead of spot prices could have prevented the mispricing of wBETH. More broadly, critical risk management systems should not rely on potentially manipulable market data. An independent oracle system with multi-source aggregation and TWAP calculations provides a more robust price feed.
Over-provisioning and Redundant Infrastructure
The April 2025 AWS outage affecting Binance, KuCoin, and MEXC demonstrated the risks of centralized infrastructure dependency. Running key components across multiple cloud providers increases operational complexity and costs but eliminates correlated failures. Layer 2 networks can maintain multiple RPC providers with automatic failover. The additional costs may seem wasteful during normal operations but prevent hours of downtime during peak demand.
Enhanced Stress Testing and Capacity Planning
A system performing well under normal conditions until a failure mode indicates insufficient stress testing. Simulating 100 times normal load should be a standard practice, with identifying bottlenecks during development costing less than discovering them during an actual outage. However, realistic load testing remains challenging. Production traffic exhibits patterns that synthetic tests cannot fully capture, and user behavior during an actual crash differs from that during testing.
Way Forward
Over-provisioning offers the most reliable solution but conflicts with economic incentives. Maintaining 10x excess capacity for rare events costs money daily to prevent an issue that may occur once a year. The system will continue to fail under stress until over-provisioning is proven reasonable by imposing a significant cost for catastrophic failures.
Regulatory pressure may force change. If regulations require 99.9% uptime or limit acceptable downtimes, exchanges will need to be over-engineered. However, regulations often follow disasters rather than prevent them. The collapse of Mt. Gox in 2014 led Japan to introduce formal cryptocurrency exchange regulations. The cascading event in October 2025 is likely to trigger a similar regulatory response. Whether these responses are specified outcomes (maximum acceptable downtime, maximum slippage during settlement) or implementation details (specific oracle providers, circuit breaker thresholds) remains uncertain.
The fundamental challenge is that these systems operate globally but rely on infrastructure designed for traditional business hours. When pressure hits at 2 a.m., teams scramble to deploy fixes, and users face mounting losses. Traditional markets halt trading under pressure; crypto markets simply collapse. Whether this is a feature or a flaw depends on perspective and position.
Blockchain systems have achieved significant technical sophistication in a short time. Maintaining distributed consensus among thousands of nodes represents a true engineering feat. But achieving reliability under pressure requires moving beyond prototype architectures to production-grade infrastructure. This shift requires funding and prioritizing robustness over feature development speed.
The challenge lies in how to prioritize robustness over growth during a bull market, when everyone is making money and downtime seems like someone else's problem. By the time the system is stress-tested in the next cycle, new weaknesses will emerge. The industry's response to the lessons of October 2025 will determine whether it learns or repeats a similar pattern. History suggests we will discover the next critical vulnerability through another billion-dollar failure under pressure.
Disclaimer: The content of this article solely reflects the author's opinion and does not represent the platform in any capacity. This article is not intended to serve as a reference for making investment decisions.
You may also like
Bitcoin price to 6X in 2026? M2 supply boom sparks COVID-19 comparisons
Whale ‘BitcoinOG’ Boosts $227M Short, Sends $587M BTC to CEXs
ARK Bitcoin Purchase Totals $162.85 Million Amid Crypto Growth
[English Long Tweet] Is USDe Really Safe Enough?