W skrócie
- DeepSeek V4 może pojawić się w ciągu kilku tygodni, celując w elitarną wydajność kodowania.
- Według osób z branży, może przewyższyć Claude i ChatGPT w zadaniach związanych z długim kontekstem kodu.
- Deweloperzy są już podekscytowani perspektywą potencjalnej rewolucji.
Według doniesień, DeepSeek planuje wypuścić swój model V4 około połowy lutego i jeśli wewnętrzne testy są jakąkolwiek wskazówką, giganci AI z Doliny Krzemowej powinni być zaniepokojeni.
Startup AI z Hangzhou może celować w premierę około 17 lutego — czyli naturalnie podczas Księżycowego Nowego Roku — z modelem specjalnie zaprojektowanym do zadań związanych z kodowaniem, według
. Osoby bezpośrednio zaangażowane w projekt twierdzą, że V4 przewyższa zarówno Claude od Anthropic, jak i serię GPT od OpenAI w wewnętrznych benchmarkach, zwłaszcza w obsłudze wyjątkowo długich promptów kodowych.
Oczywiście, żaden benchmark ani informacje o modelu nie zostały publicznie udostępnione, więc nie można bezpośrednio zweryfikować tych twierdzeń. DeepSeek również nie potwierdził tych pogłosek.
Społeczność deweloperów jednak nie czeka na oficjalne informacje. Subreddity r/DeepSeek i r/LocalLLaMA już się rozgrzewają, użytkownicy gromadzą kredyty API, a entuzjaści na X szybko dzielą się przewidywaniami, że V4 może ugruntować pozycję DeepSeek jako zadziornego outsidera, który nie gra według miliardowych reguł Doliny Krzemowej.
Anthropic zablokował subskrypcje Claude w aplikacjach firm trzecich, takich jak OpenCode, i podobno odciął dostęp xAI i OpenAI.
Claude i Claude Code są świetne, ale jeszcze nie 10 razy lepsze. To tylko zmusi inne laboratoria do szybszego rozwoju modeli/agentów kodujących.
Plotka głosi, że DeepSeek V4 ma się pojawić…
— Yuchen Jin (@Yuchenj_UW) 9 stycznia 2026
To nie byłaby pierwsza rewolucja DeepSeek. Gdy firma wypuściła swój model rozumowania R1 w styczniu 2025 roku, wywołało to wyprzedaż na światowych rynkach o wartości 1 biliona dolarów.
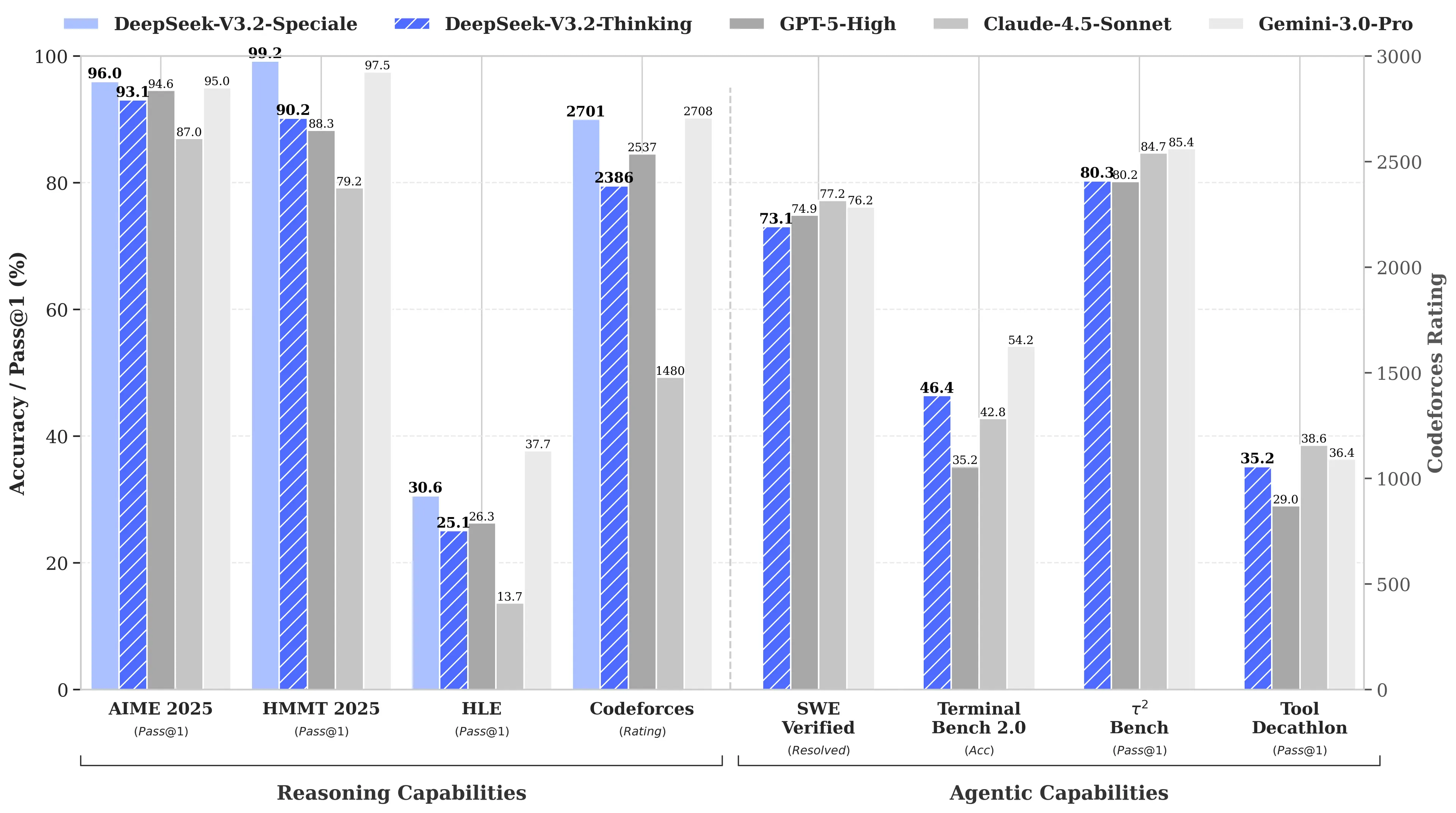
Powód? R1 od DeepSeek dorównywał modelowi o1 od OpenAI w benchmarkach matematycznych i logicznych, mimo że jego opracowanie kosztowało podobno jedynie 6 milionów dolarów — czyli około 68 razy mniej niż wydatki konkurencji. Jego model V3 osiągnął później 90,2% w benchmarku MATH-500, wyprzedzając 78,3% Claude, a najnowsza aktualizacja “V3.2 Speciale” jeszcze bardziej poprawiła jego wyniki.
Obraz: DeepSeek
Skupienie się V4 na kodowaniu byłoby strategicznym zwrotem. Podczas gdy R1 koncentrował się na czystym rozumowaniu — logice, matematyce, dowodach formalnych — V4 to model hybrydowy (zadania rozumowania i nierozumowania), skierowany do rynku deweloperów korporacyjnych, gdzie generowanie kodu o wysokiej dokładności przekłada się bezpośrednio na przychody.
Aby zdobyć dominację, V4 musiałby pokonać Claude Opus 4.5, który obecnie utrzymuje rekord SWE-bench Verified na poziomie 80,9%. Jednak jeśli wcześniejsze premiery DeepSeek są jakąkolwiek wskazówką, osiągnięcie tego celu może nie być niemożliwe, nawet przy wszystkich ograniczeniach, z jakimi boryka się chińskie laboratorium AI.
Niespecjalnie tajny składnik
Zakładając, że pogłoski są prawdziwe, jak to małe laboratorium może osiągnąć taki wyczyn?
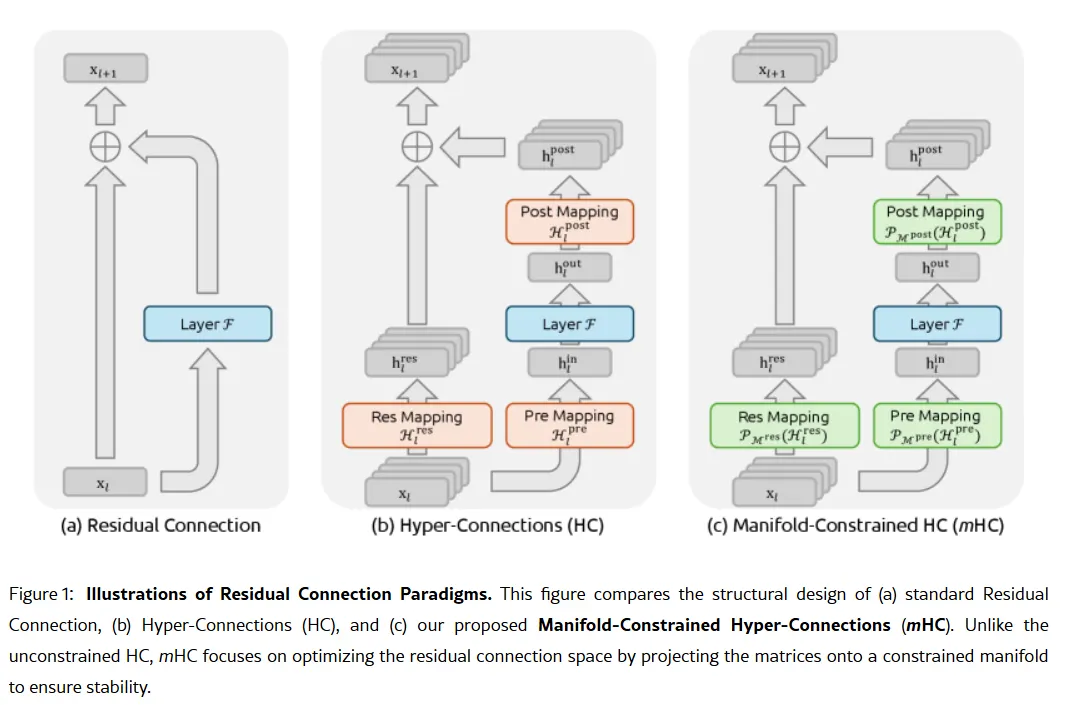
Tajna broń firmy mogła zostać opisana w pracy naukowej z 1 stycznia: Manifold-Constrained Hyper-Connections, czyli mHC. Współautorem jest założyciel Liang Wenfeng, a nowa metoda trenowania rozwiązuje fundamentalny problem skalowania dużych modeli językowych — jak zwiększyć pojemność modelu bez jego destabilizacji lub „eksplozji” podczas treningu.
Tradycyjne architektury AI zmuszają całą informację do przechodzenia przez jeden wąski kanał. mHC poszerza tę ścieżkę do wielu strumieni, które mogą wymieniać informacje bez powodowania załamania treningu.
Obraz: DeepSeek
Wei Sun, główny analityk AI w Counterpoint Research, nazwała mHC „uderzającym przełomem” w komentarzu dla
. Według niej ta technika pokazuje, że DeepSeek może „ominąć ograniczenia wydajnościowe i odblokować skokowy wzrost inteligencji”, nawet przy ograniczonym dostępie do zaawansowanych chipów z powodu amerykańskich ograniczeń eksportowych.
Lian Jye Su, główny analityk w Omdia, zauważył, że gotowość DeepSeek do publikowania swoich metod sygnalizuje „nowo odkrytą pewność siebie chińskiego przemysłu AI”. Otwarte podejście firmy sprawiło, że stała się ulubieńcem deweloperów, którzy widzą w niej to, czym kiedyś była OpenAI, zanim przeszła na zamknięte modele i miliardowe rundy finansowania.
Nie wszyscy są przekonani. Niektórzy deweloperzy na Reddicie narzekają, że modele rozumowania DeepSeek marnują zasoby obliczeniowe na proste zadania, podczas gdy krytycy twierdzą, że benchmarki firmy nie odzwierciedlają realnych warunków. Jeden wpis na Medium zatytułowany "DeepSeek jest do bani — i już nie udaję, że jest inaczej" stał się wiralem w kwietniu 2025, oskarżając modele o generowanie „szablonowych nonsensów z błędami” i „wymyślonych bibliotek”.
DeepSeek niesie też pewne obciążenia. Problemy z prywatnością nękały firmę, a niektóre rządy zakazały natywnej aplikacji DeepSeek. Powiązania firmy z Chinami oraz pytania o cenzurę w jej modelach dodają geopolitycznego tarcia do debat technicznych.
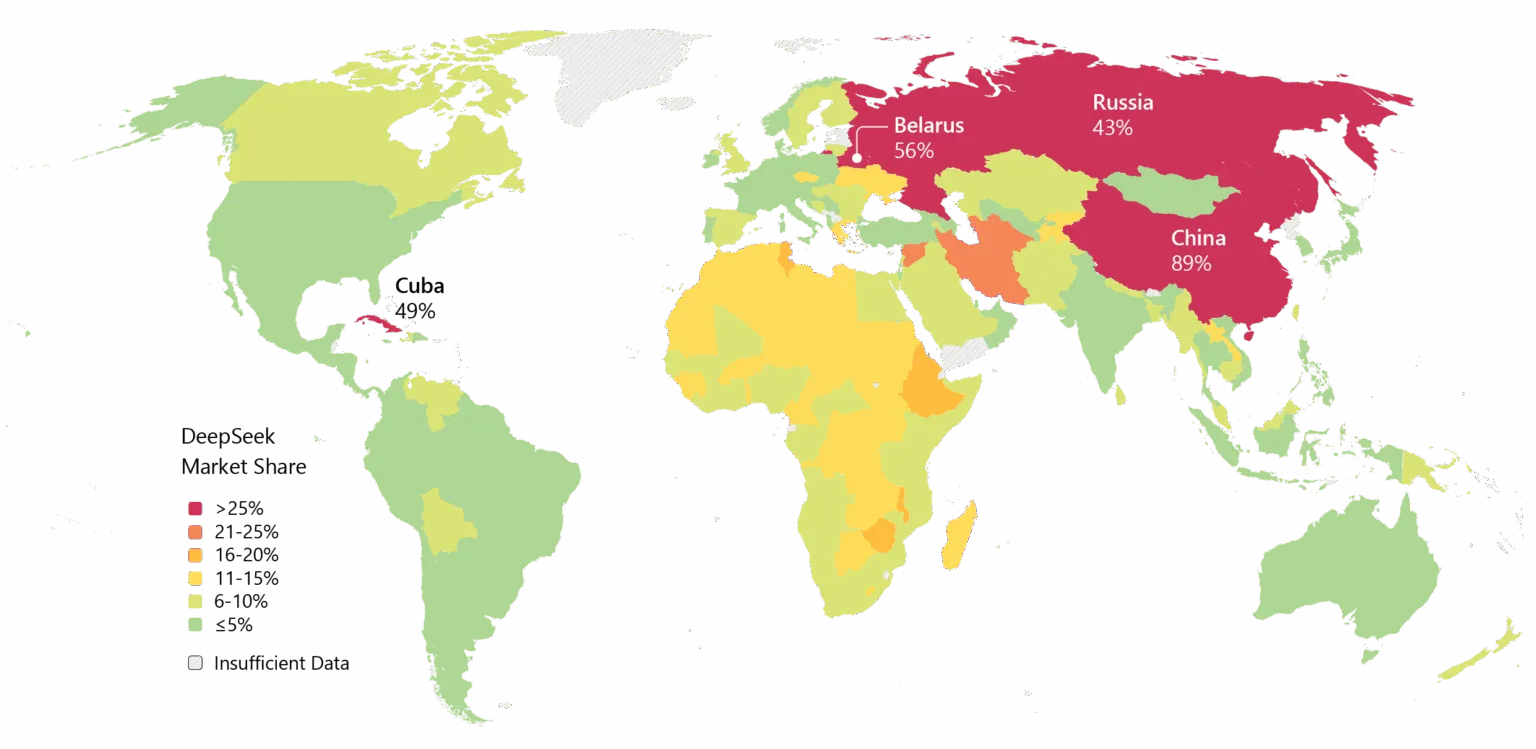
Mimo to, impet jest niezaprzeczalny. DeepSeek został szeroko przyjęty w Azji, a jeśli V4 spełni obietnice dotyczące kodowania, adopcja korporacyjna na Zachodzie może być następna.
Obraz: Microsoft
Jest też kwestia czasu. Według
, DeepSeek pierwotnie planował wypuścić model R2 w maju 2025, ale wydłużył okres przygotowań, gdy założyciel Liang nie był zadowolony z jego wyników. Teraz, gdy V4 podobno celuje w luty, a R2 może pojawić się w sierpniu, firma porusza się w tempie sugerującym pilność — lub pewność siebie. A może jedno i drugie.

